This week is the Neural Information Processing Systems workshop in Vancouver and Whistler — apparently, skiers and snowboarders are quite well represented in the AI and neuroscience communities. I enjoy the conference and get a lot out of it, but I do tend to find academic conferences have a fair bit of “angels on the head of a pin” aspect to them, and I don’t really feel very much at home with large swaths of the academic Machine Learning community, who have a passion for stats that I can only admire from a distance. It’s been clear to me for some time now that as much as I enjoy research, my path is destined to take me out of the ivory tower into industrial research and development.
That’s not to say NIPS isn’t interesting. I snuck away from my work in Yaletown to hear Joshua Tenenbaum speak today. I think he’s doing some fascinating work, that I’ve been following for a while now.
Since about 1990, AI has been revolutionised by using probabilities, rather than rules, to model human-intelligence-type tasks. This is what powers Google, and computer vision, and other recent successes in AI. However, it was generally felt that this was just a hack, and that the mind processes experience through an inate structure — the most famous proponent of this being, of course, Noam Chomsky. What Josh and other people his area are working on is empirical, rather than structural models, of the brain. In a series of clever experiments, they show that, for certain problems at least, the brain really does seem to make guesses in a Bayesian probabilistic way, just like (much of) Machine Learning. Nobody knows why or how — clearly, we don’t have Bayesian solvers embedded in our heads doing Monte Carlo sampling — but the fact that the solutions are often the same opens the possibility that Machine Learning and Cognitive Science may yet be linked in much more profound way that was thought about five or ten years ago.
Anyway, if you’re a machine learning person and you want more info, you know how to get it. But if you’re not, I highly recommend you check out this article from The Economist about Josh Tenenbaum and Thomas Griffith’s work. It’s really fascinating stuff. I linked to it before, on the previous incarnation of my blog, but that link is long gone, now, and a little reposting never hurt anyone, now did it?
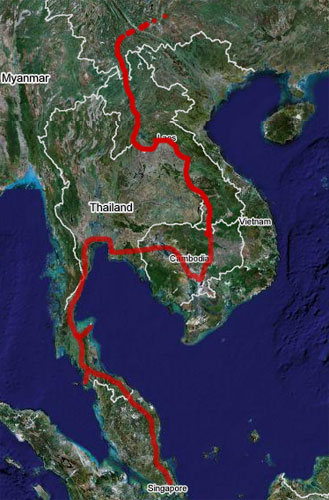
 The past few days, I’ve been running various errands for my trip to southeast Asia. I went to MEC and got a bunch of travelly items, including a new bag (30L; I’ll be flying a lot, so my plan is to get everything I need into a carryon bag). I’ll post my packing list later. Today, I got my watch fixed, confirmed some bookings and printed out all the paperwork and guides I’ll ever need. Next week, I visit the dentist, the optometrist and the immunization clinic (still need another Hepatitis B shot).
The past few days, I’ve been running various errands for my trip to southeast Asia. I went to MEC and got a bunch of travelly items, including a new bag (30L; I’ll be flying a lot, so my plan is to get everything I need into a carryon bag). I’ll post my packing list later. Today, I got my watch fixed, confirmed some bookings and printed out all the paperwork and guides I’ll ever need. Next week, I visit the dentist, the optometrist and the immunization clinic (still need another Hepatitis B shot). For the past several weeks, I’ve been setting up Machine Learning algorithms that allow machines to learn things about web pages. This is all very well and good — the algorithms work. Now it’s training time. Training means that you have to not only give the computers the data (the web pages), but for each datum, tell it what you want it to learn — “this is a good page”, “this is a bad page”, “this is a page about Buffy the Vampire Slayer“, whatever. And machines are so damned literal. Give the machine a set of Buffy wikipedia articles and science blogs, and it will most likely learn how to distinguish blogs from wikipedia articles (because it’s simpler), and not physics from Buffy.
For the past several weeks, I’ve been setting up Machine Learning algorithms that allow machines to learn things about web pages. This is all very well and good — the algorithms work. Now it’s training time. Training means that you have to not only give the computers the data (the web pages), but for each datum, tell it what you want it to learn — “this is a good page”, “this is a bad page”, “this is a page about Buffy the Vampire Slayer“, whatever. And machines are so damned literal. Give the machine a set of Buffy wikipedia articles and science blogs, and it will most likely learn how to distinguish blogs from wikipedia articles (because it’s simpler), and not physics from Buffy.